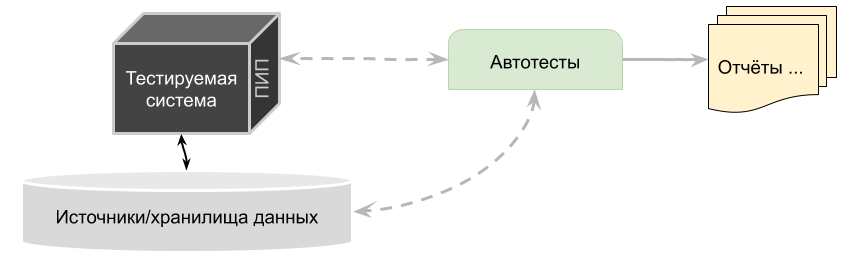
Some "C.O"-like ideas about back-end and BigData(ETL) test automation:
1. Conceptually the back-end testing approach may look like:
 2. In case of BigData ETL(Extract-Transform-Load) application:
2. In case of BigData ETL(Extract-Transform-Load) application:
 There is no huge difference but:
There is no huge difference but:
а. your tests interact with some schedulers and other "auxiliarry" tools now.
b. there is no direct response from the system-under-test(requests-response-check turns into request for launch-wait-check output data).
c. test data approach (in terms of libraries to use) - is quite similar.
d. since there is no direct interaction with SUT there are more libraries in your test automation project.
e. Output data checks often contain "does look like truth?"-like checks.
1. Conceptually the back-end testing approach may look like:


а. your tests interact with some schedulers and other "auxiliarry" tools now.
b. there is no direct response from the system-under-test(requests-response-check turns into request for launch-wait-check output data).
c. test data approach (in terms of libraries to use) - is quite similar.
d. since there is no direct interaction with SUT there are more libraries in your test automation project.
e. Output data checks often contain "does look like truth?"-like checks.