Просто наблюдение "внимательного индейца Джо":
1. На уровне "квадратиков" подход к авто-тестированию тылового междумордия( ПИП) выглядит так:

2. А вот в случае всяких большеданных приложений типа "Взять-Преобразовать-Выдать":
 Великой разницы нет, почти те же самые тесты на междумордий, однако:
Великой разницы нет, почти те же самые тесты на междумордий, однако:
а. работать приходится не с самим приложением, а с некими дополнительными приспособами которые запускают уже само приложение и т.д.
б. непосредственного ответа от тестируемого приложения может и не быть ("запрос - ответ - проверка что там в ответе пришло" меняется на "запрос на запуск - ожидание - проверка данных в выдаче")
в. работа со входными-выходными данными (на уровне библиотек и вызовов) - практически такая же.
г. за счёт работы через "посредников" количество дополнительных библиотек в проекте возрастает.
д. Сами проверки выхлопа часто включают в себя "похоже ли на правду" ибо при больших объёмах жёстко сравнивать вход-выход может быть ооооочень дорого.
1. На уровне "квадратиков" подход к авто-тестированию тылового междумордия( ПИП) выглядит так:
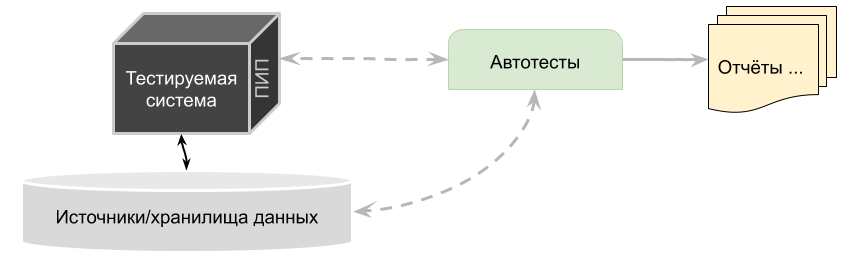
2. А вот в случае всяких большеданных приложений типа "Взять-Преобразовать-Выдать":

а. работать приходится не с самим приложением, а с некими дополнительными приспособами которые запускают уже само приложение и т.д.
б. непосредственного ответа от тестируемого приложения может и не быть ("запрос - ответ - проверка что там в ответе пришло" меняется на "запрос на запуск - ожидание - проверка данных в выдаче")
в. работа со входными-выходными данными (на уровне библиотек и вызовов) - практически такая же.
г. за счёт работы через "посредников" количество дополнительных библиотек в проекте возрастает.
д. Сами проверки выхлопа часто включают в себя "похоже ли на правду" ибо при больших объёмах жёстко сравнивать вход-выход может быть ооооочень дорого.
